RetinaNet - Focal Loss for Dense Object Detection 논문 리뷰
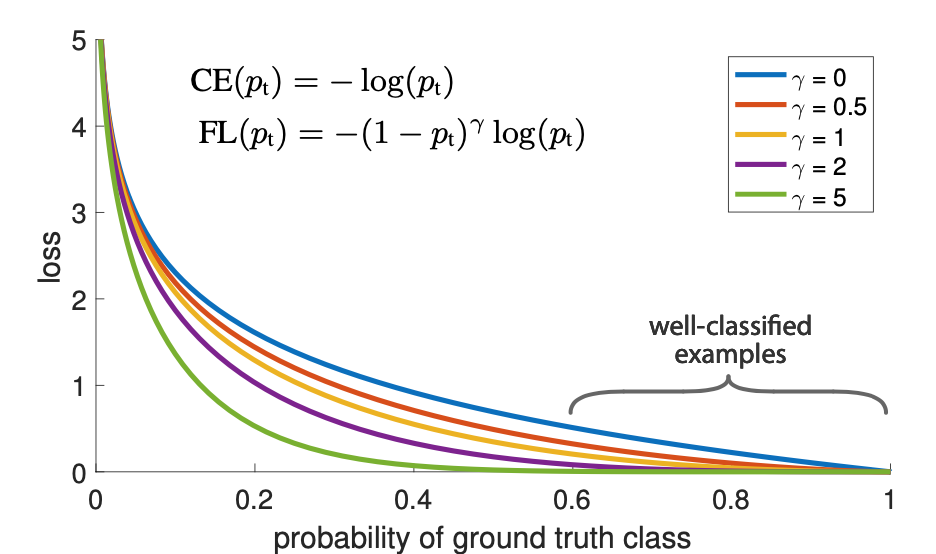
Figure 1.
- Standard cross entropy 기준에서 $(1-p_x)^r$을 더해 Focal Loss라는 방식을 제안
- $(r>0)$을 설정할 시에 잘 분류된 $(p_t > 0.5)$의 Loss값이 줄어들어 잘못 분류된 샘플에 초점을 더욱 줄 수 있다.
- 이와 같은 Focal Loss는 대량의 background examples가 있는 상태에서 매우 정확하게 Detection이 가능하다.
CE : Cross Entropy
FL : Focal Loss
Abstract
- 현재까지의 가장 높은 정확도를 보이는 모델은 two-stage을 기반으로 널리 쓰이는 R-CNN이 있다.
- 이때 classification은 sparse set of candidate object locations을 기반으로 진행
- 1-stage의 경우 더욱 빠르고 간단하다는 점을 가지고 있지만, 2-stage의 경우 accuracy값이 떨어졌다는 것을 볼 수 있다.
- 이는 extreme foreground-background class가 불균형이 원인
- 이를 보완하기 위해 분류가 잘 된 class에 down-weights를 위해 standard cross entropy를 재구성
- FC(Focal Loss)는 hard examples에 초점을 맞추고 negatives sets가 훈련중에 예측에 영향을 미치는 것을 방지
- 위와 같은 방식의 손실의 효율성을 평가하기 위해 RetinaNet이라는 simple dense detector을 설계하고 훈련을 진행
- 훈련을 진행한 결과 RetinaNet이 기존 2-stage에서 정확도가 증가했고, 1-stage와 속도를 평준화 시킬 수 있었음
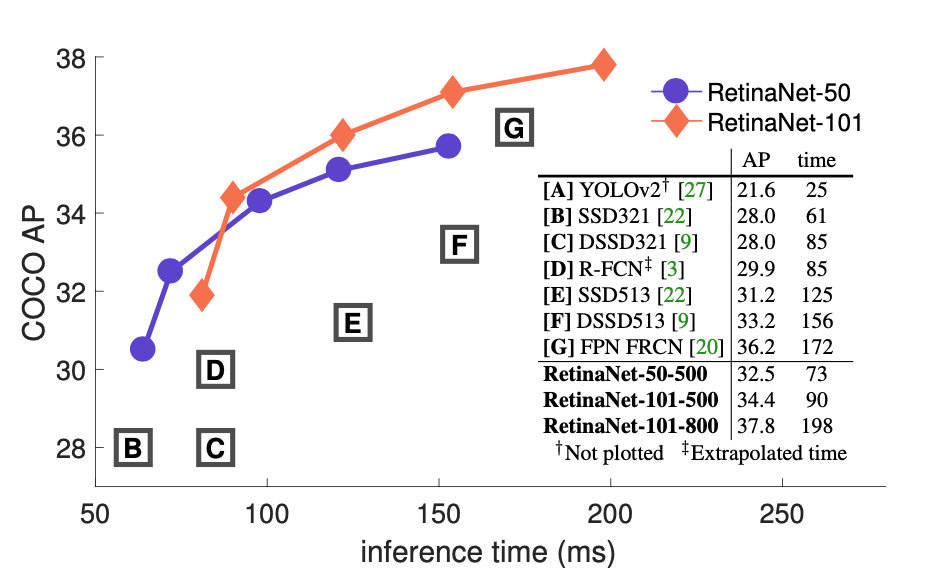
Figure 2
- Speed(ms) VS accuracy(AP : Average Precision)
- Focal loss로 인한 simple one-stage RetinaNet Detection은 Faster R-CNN보다 성능이 뛰어난 것을 볼 수 있음
Introduction
- 최근까지 발표된 Object detectors는 2-stage의 매커니즘을 기반
- R-CNN 프레임워크를 참고해 1-stage에선 object location의 sets을 생성하고, 2-stage에선 각 위치를 foreground classes 중 하나로 분류하거나 background를 Convolutional neural network로 분류
1-stage와 비슷한 정확도를 얻을 수 있는가?
- 1-stage는 location, scale, ratio를 기반해 적용
-
YOLO나 SSD와 같은 모델은 2-stage보다 1-stage에서 10~40%이내의 정확도와 더 빠른 속도를 제공
- RetinaNet은 1-stage에서 정확도의 방해가 되는 요소를 식별하고 이를 제거하는 새로운 손실함수(Focal Loss)를 제안
-
클래스 불균형은 2-staged의 casade와 샘플링 휴리스틱을 이용해 해결
- 1-stage detector는 이미지 전체에서 샘플링되는 location을 처리해야한다.
- 이 과정에서 location, scale, ratio를 열거?(cover)을 하게 되는데, 이때 휴리스틱을 적용할 수 있지만 background에 의해 분류가 되기 때문에 비효율적임
- 이는 bootstrapping을 통해 해결되는 detection의 고전적인 문제
bootstrapping : 무작위 표본 추출에 의존하는 어떤 시험이나 계측. 부트스트랩은 표본 추정치들의 정확도를 할당할 수 있도록 함
- Focal Loss를 통해 정답인 클래스의 신뢰도가 증가함에 따라 스케일링 계수가 0으로 감소
- 이를 통해 쉬운 문제는 모델에 관여하는 것을 자동으로 낮출 수 있다.
- 훈련을 통해 어려운 문제에 모델을 빠르게 집중시킴
-
실험에 따르면 Focal Loss를 사용할 시에 샘플링 휴리스틱이나 hard-example mining을 사용할 때보다 더욱 효율적인 학습을 진행할 수 있음
- Focal Loss를 입증하기 위해 input image에서 location을 샘플링한 모델을 RetinaNet으로 1-stage에서 Detection을 설계
- Its design features an efficient in-network feature pyramid and use of anchor boxes
→ 해석? : 이 구조는 효율적인 네트워크 피라미드와 앵커박스가 특징이다
Anchor box
- ResNet-101- FPN 백본을 기반으로 하는 RetinaNet은 5fps로 실행하면서 39.1의 COCO AP를 달성할 수 있었다.
Related Works
- Classic Object Detectors
- Two-stage Detectors
- One-stage Detectors
- Class Imbalance
- Robust Estimation : 주성분 로지스틱회귀
Focal Loss
- foreground와 background사이에 불균형이 발생하는 1-stage detection을 해결하기 위함
- 이진 분류를 위한 CE(Cross Entropy) Loss에서 시작
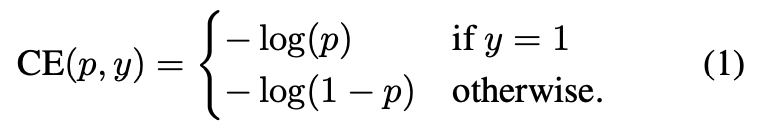
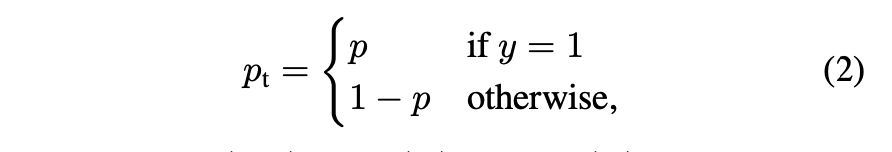
- $CE(p,y) = CE(pt) = -log(p_t)$로 재정의
- CE Loss는 밑의 그림에서 파란색으로 조회 가능
- 이때 주목할 점은 표를 보면 $(pt > 0.5)$보다 loss를 야기함
- 이렇게 대량의 easy examples를 요약한다면 작은 loss값으로 hard examples를 해결 가능
Balanced Cross Entropy
- 클래스 불균형을 해결하는 방법은 Class 1에 대해 가중치 계수 $\alpha \in [0,1]$을 도입하고 , Class -1에 대해 $1 - \alpha$을 도입한다
- $\alpha$는 inverse class frequency에 의해 설정되거나 교차 검증에 의해 설정되는 하이퍼 파라미터로 설정할 수 있음
- $p_t$를 정의한 방법과 유사하게 $a_t$를 정의한다.
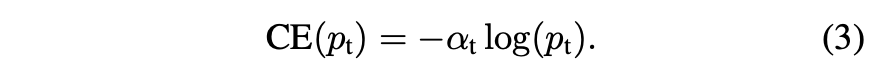
- 이는 CE에 대한 확장이며 Focal Loss에 대한 실험을 기준으로 했다.
Focal Loss Definition
- 위의 그래프 실험에서 알 수 있듯이 클래스 불균형은 Cross Entropy Loss를 야기한다.
- 쉬운 예제가 Loss를 구성하고, gradient에 상당히 많은 관여가 일어난다
- 이는 hard examples를 해결하기엔 역부족이다.
- 이를 보완하기 위해 Loss function을 변형하여 easy examples의 가중치를 낮추고, hard examples에 초점을 둔다.
- 이때 tunable focusing parameter $\gamma \geqq 0$을 사용하여 modulation factor $(1-p_t)^\gamma$을 추가할 것을 제안
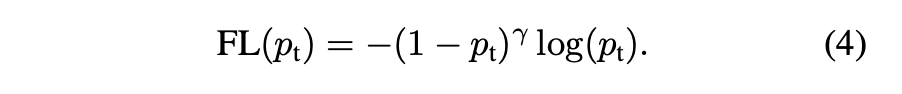
- Focal Loss는 $\gamma \in [0,5]$의 값에 대해 시각화가 이루어짐
- Focal Loss의 두가지 속성
- $p_t$가 작으면 modulating factor가 1에 가까워지며 loss는 영향을 받지 않음
- Focusing Parameter $\gamma$는 easy examples의 down-weight에 대해 부드럽게 조정
- $\gamma = 0$일 때 FL는 CE와 동일하고 $\gamma$가 증가하면 modulating factor의 효과도 마찬가지로 증가했다
- 즉, modulating factor는 easy examples에서 loss의 기여도를 줄이고, 낮은 Loss를 받는 범위를 확장시킨다.
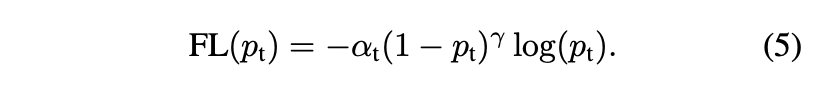
- $\alpha$-balanced가 없는 것에 비해 정확도가 개선이 되었기에 이 형태를 채택
- 마지막으로, Loss layer의 구현은 $p$ 계산을 위한 sigmoid operation과 Loss computation을 결합해 안정성을 제공한다
- 실험 결과에서는 위의 Focal Loss를 사용하지만 형태는 중요하지 않고, Focal Loss의 다른 인스턴스화를 고려하고 이 방안이 똑같이 효과적인 것을 보여줌
### Class Imbalance and Model Initialization
- 이진 분류 모델은 기본적으로 $y= -1 \ or \ 1$을 출력할 동일한 확률을 갖도록 초기화가 된다.
- 이 초기화 과정에서 클래스 불균형이 존재하는 경우 클래스로 인한 Loss가 전체의 Loss 값을 관여하고 불안정성을 early training에서 유발할 수 있음
- 이에 대응하기위해 학습 시작 시에 rare class(foreground)에 대한 모델에서 예측한 값에 대한 ‘prior’개념을 도입
- prior은 $\pi$로 표시하고 rare class의 examples에 대한 모델의 추정값 $p$를 낮춰서 설정($p=0.01)$
- 이는 Loss function이 아닌 Model Initialization의 변경사항이다.
- 클래스 불균형이 심한 경우 CE 및 FL 모두에 대한 훈련 안정성을 향상시키는 것으로 나타났음
### Class Imbalance and Two-stage Detectors
- 2-stage Detector는 $a-balancing$과 Focal Loss를 제외한 CE(Cross Entropy)을 통해 훈련
- 대신 다음 두개의 매커니즘을 통해 Class Imbalance를 해결
- 2-stage cascade
- biased minibatch sampling
- The first cascade stage is an object proposal mechanism [35, 24, 28] that reduces the nearly infinite set of possible object locations down to one or two thousand. Importantly, the selected proposals are not random, but are likely to correspond to true object locations, which removes the vast majority of easy negatives. → 해석 불가..
- 두번째 단계를 훈련시킬 때 biased sampling은 일반적으로 Positive : Negative = 1:3의 비율을 포함하는 미니 배치를 구성하는데 사용
- 이 비율은 샘플링을 통해 구현되는 암시적 $a-balancing \ factor$와 같다
- Focal Loss는 손실 기능을 통해 1단계 Detection System에서 이러한 매커니즘을 해결하도록 설계
## RetinaNet Detector
- 백본 네트워크와 two task-specific subnetworks로 구성된 단일 통한 네트워크
- 백본은 전체 입력이미지에 대한 Convolution Feature Map을 계산하는 역할을 하며 독립형 Convolutional Network이다.
- 첫번째 subnet은 백본의 출력에 대한 Detection을 수행
- 두번째 subent은 convolution bounding box regression을 수행
- 두개의 하위 네트워크는 dense detection과 figure을 탐지할 수 있는 단순한 one-stage로 구성되어 있다.
-
이때 Parameters는 sensitive하게 반응하지 않는다.
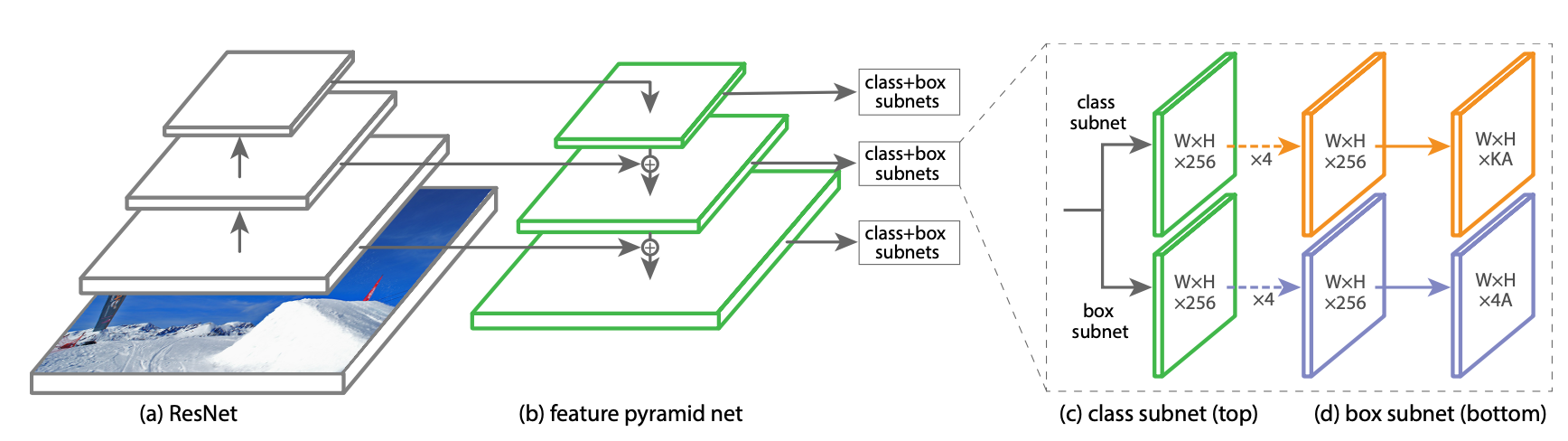
### Feature Pyramid Network Backbone
- FPN(Feature Pyramid Network)
- RetinaNet의 백본 네트워크
- FPN은 top-down pathway와 측면 연결을 통해 standard Convolutional Network를 확장하므로 single resolution input image에서 multi-scale feature pyramid를 효율적으로 구성
- 피라미드의 각 레벨은 각자 다른 scale에서 detecting하는데 사용할 수 있음
- FPN은 RPN 및 DeepMask의 스타일 뿐만 아니라 Fast R-CNN과 같은 2-stage Detectio에서 얻은 결과에서 알 수 있듯이 FPN에서 multi scale 예측을 향상시킨다
- Mask R-CNN, ResNet 구조 위에 FPN을 구축하면 $p_3 \ to \ p_7$까지의 피라미드를 구성하는데, 이때 $p_i$의 i는 피라미드 레벨을 나타낸다.($p_i$는 입력보다 해상도가 $2^i$가 낮다.)
- 모든 피라미드엔 채널 수가 256이다
### Anchor
- RPN 변형에 있는 것과 유사한 translation-invariant anchor box를 사용한다
- Anchor는 피라미드 레벨 3에서 7까지 $32^2$에서 $512^2$의 면적을 가지고 있다.
- 피라미드 수준에서는 세가지 비율 {1 : 2, 1 : 1, 2 : 1}의 앵커를 사용
- 이때 dense scale coverage를 위해 각 레벨에서 3개의 사이즈 {20, 2^(1/3), 2^(2/3)}의 앵커를 추가한다.
- 이를 통해 AP를 향상시킬 수 있는데, 전체적으로 레벨 당 A = 9 개의 앵커가 있으며 레벨 전반에 걸쳐 네트워크의 입력 이미지와 관련하여 32-813픽셀을 포함한다.
- 각 앵커에는 분류 대상의 길이 K가 one-hot 벡터로 주어지는데, 이때 K는 object class의 수이고 box regression targets의 4벡터이다.
- RPN의 구조를 따르지만 다중 클래스 감지 및 adjusted thresholds을 수정했다.
- 특히 앵커는 0.5의 Intersection-over-union(IoU)를 사용하여 Ground-Truth에 할당된다.
- IoU [0,0.4]에 있으면 background로 할당하고, 각 앵커가 최대 하나의 object box로 할당되므로 길이 K 레이블 벡터의 해당 항목을 1로 설정하고 다른 모든 항목을 0으로 설정한다.
- 이때 앵커가 할당되지 않은 경우 [0.4,0.5]에서 충돌이 발생할 수 있지만 이는 훈련 중에는 무시한다.
- 또한 box regression targets는 각 앵커와 할당된 object box 사이의 오프셋으로 계산되거나 할당되지 않았을 경우 생략이 된다.
### Classification Subnet
- A(Anchor) 및 K(Object Class) 각각에 대해 각 공간 위치에서 객체가 존재할 확률을 예측
- 이 서브넷은 각 FPN 레벨에 연결된 작은 FCN이다.
- 이 서브넷의 parametors는 모든 피라미드 수준에서 공유가 된다.
- 구조는 주어진 피라미드 레벨에서 C(Channel)이 있는 input feature map을 가져오면 서브넷은 각각 채널 필터가 있고, ReLU가 뒤 따르는 4개의 33 conv 레이어를 적용한 다음 KA필터가 있는 33 conv 레이어를 적용한다. 마지막으로 시그모이드를 사용하여 공간 위치당 KA binary classification을 한다.
- 이때 대부분 C = 256, A = 9를 사용한다
- RPN과 달리 이 서브넷은 depth가 깊고 3*3 conv만 사용하여 box regression subnet과 parametors를 사용하지 않는다는 특징을 가지고 있다.
- 이러한 설계구조는 하이퍼 파라미터의 특정한 값보다 더 중요하다는 것을 발견할 수 있었다.
### Box Regresion Subnet
- Classification Subnet과 병행하여 각 앵커 박스의 오프셋을 근처의 ground-truth object(존재하는 경우)로 Regression하기 위해 각 피라미드 레벨에 또 작은 FCN을 연결한다.
- BRS의 구조는 공간 위치 당 4A linear outputs에서 종료된다는 점을 제외하고, Classification Subnet과 동일하다.
- 공간 위치당 A에 대해 4개의 출력은 앵커와 Ground-Truth Box 간의 상대적 오프셋을 예측한다.
- 이때 가장 최근의 모델과 달리 더 적은 매개 변수를 사용하는 클래스에 구애받지 않는 class-agnostic bounding box regressor을 사용하며 효과적인 것을 볼 수 있었다
- Classification Subnet과 Box Regression Subnet은 공통 구조를 공유하지만 별도의 매개 변수를 사용한다